
Outcome-Oriented Predictive Process Monitoring on Positive and Unlabelled Event Logs
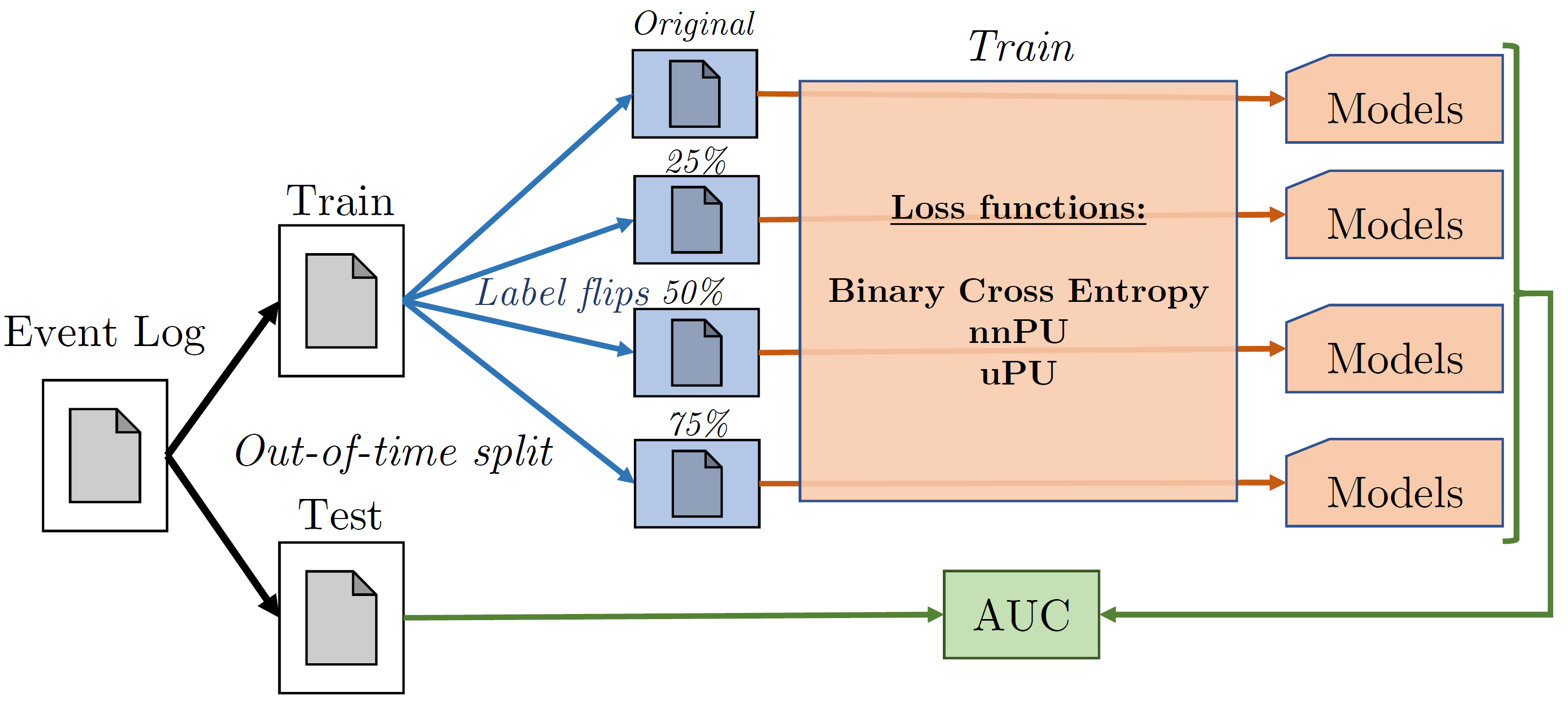
A lot of recent literature on outcome-oriented predictive process monitoring focuses on using models from machine and deep learning. In this literature, it is assumed the outcome labels of the historical cases are all known. However, in some cases, the labelling of cases is incomplete or inaccurate. For instance, you might only observe negative customer feedback, fraudulent cases might remain unnoticed. These cases are typically present in the so-called positive and unlabelled (PU) setting, where your data set consists of a couple of positively labelled examples and examples which do not have a positive label, but might still be examples of a positive outcome. In this work, we show, using a selection of event logs from the literature, the negative impact of mislabelling cases as negative, more specifically when using XGBoost and LSTM neural networks. Furthermore, we show promising results on real-life datasets mitigating this effect, by changing the loss function used by a set of models during training to those of unbiased Positive-Unlabelled (uPU) or non-negative Positive-Unlabelled (nnPU) learning.
Publication
- Jari Peeperkorn, Carlos Ortega Vázquez, Alexander Stevens, Johannes De Smedt, Seppe vanden Broucke, Jochen De Weerdt, “Outcome-Oriented Predictive Process Monitoring on Positive and Unlabelled Event Logs”, Process Mining Workshops (ML4PM), ICPM 2022, https://doi.org/10.1007/978-3-031-27815-0_19