
Trace Clustering
Model-driven Stochastic Trace Clustering
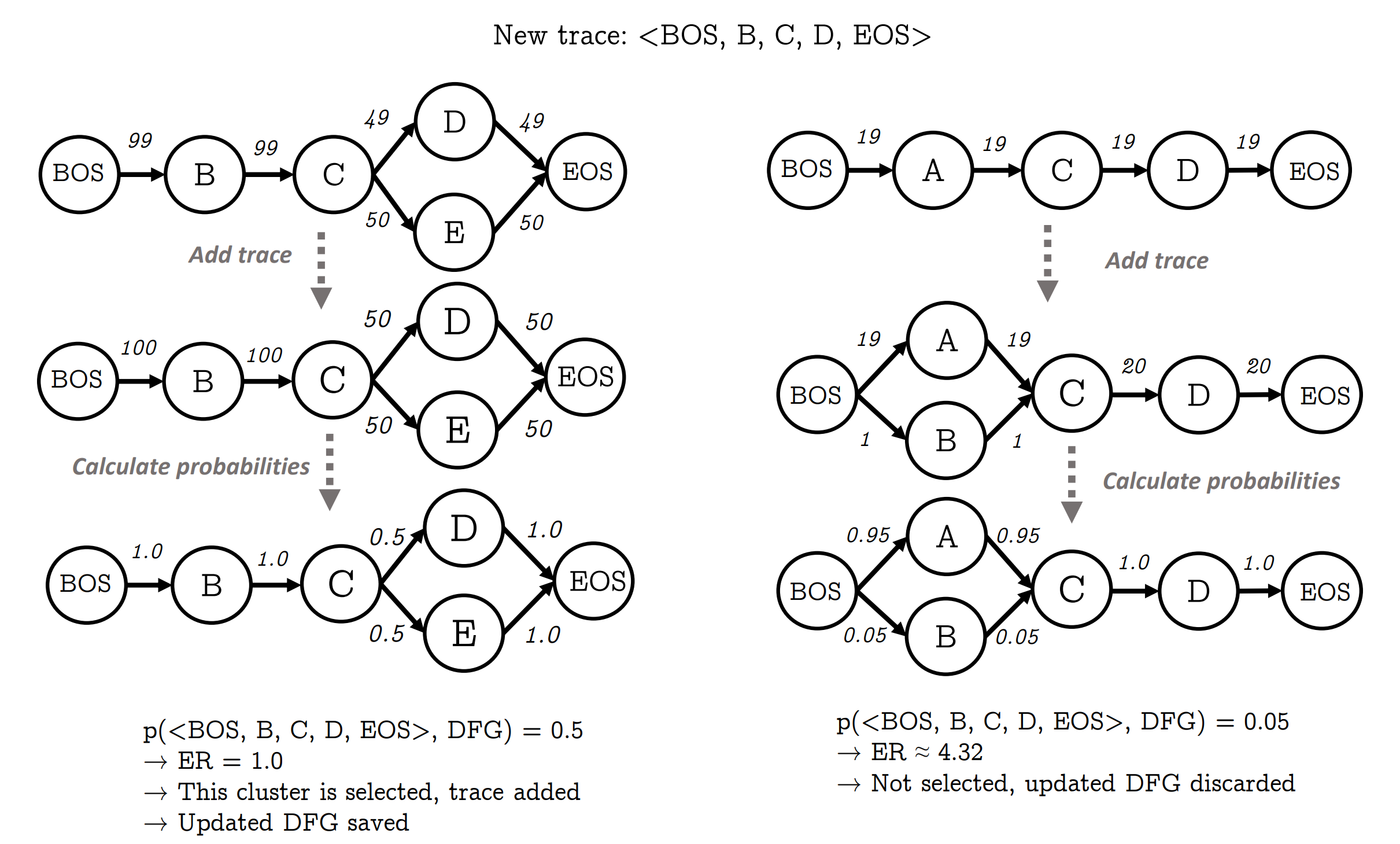
Process discovery algorithms automatically extract process models from event logs, but high variability often results in complex and hard-to-understand models. To mitigate this issue, trace clustering techniques group process executions into clusters, each represented by a simpler and more understandable process model. Model-driven trace clustering improves on this by assigning traces to clusters based on their conformity to cluster-specific process models. However, most existing clustering techniques rely on either no process model discovery, or non-stochastic models, neglecting the frequency or probability of activities and transitions, thereby limiting their capability to capture real-world execution dynamics. We propose a novel model-driven trace clustering method that optimizes stochastic process models within each cluster. Our approach uses entropic relevance, a stochastic conformance metric based on directly-follows probabilities, to guide trace assignment. This allows clustering decisions to consider both structural alignment with a cluster’s process model and the likelihood that a trace originates from a given stochastic process model. The method is computationally efficient, scales linearly with input size, and improves model interpretability by producing clusters with clearer control-flow patterns. Extensive experiments on public real-life datasets show that our method outperforms existing alternatives in representing process behavior and reveals how clustering performance rankings can shift when stochasticity is considered.
Preprint
- Jari Peeperkorn, Johannes De Smedt \& Jochen De Weerdt, “Model-driven Stochastic Trace Clustering”, arXiv:2506.23776