
Generalization and validation of predictive process monitoring models
Can recurrent neural networks learn process model structure?
Various methods using machine and deep learning have been proposed to tackle different tasks in predictive process monitoring, forecasting for an ongoing case e.g. the most likely next event or suffix, its remaining time, or an outcome-related variable. Recurrent neural networks (RNNs), and more specifically long short-term memory nets (LSTMs), stand out in terms of popularity. In this work, we investigate the capabilities of such an LSTM to actually learn the underlying process model structure of an event log. We introduce an evaluation framework that combines variant-based resampling and custom metrics for fitness, precision and generalization. We evaluate 4 hypotheses concerning the learning capabilities of LSTMs, the effect of overfitting countermeasures, the level of incompleteness in the training set and the level of parallelism in the underlying process model. We confirm that LSTMs can struggle to learn process model structure, even with simplistic process data and in a very lenient setup. Taking the correct anti-overfitting measures can alleviate the problem. However these measures did not present themselves to be optimal when selecting hyperparameters purely on predicting accuracy. We also found that decreasing the amount of information seen by the LSTM during training, causes a sharp drop in generalization and precision scores. In our experiments, we could not identify a relationship between the extent of parallelism in the model and the generalization capability, but they do indicate that the process’ complexity might have impact.
Experimental setup: 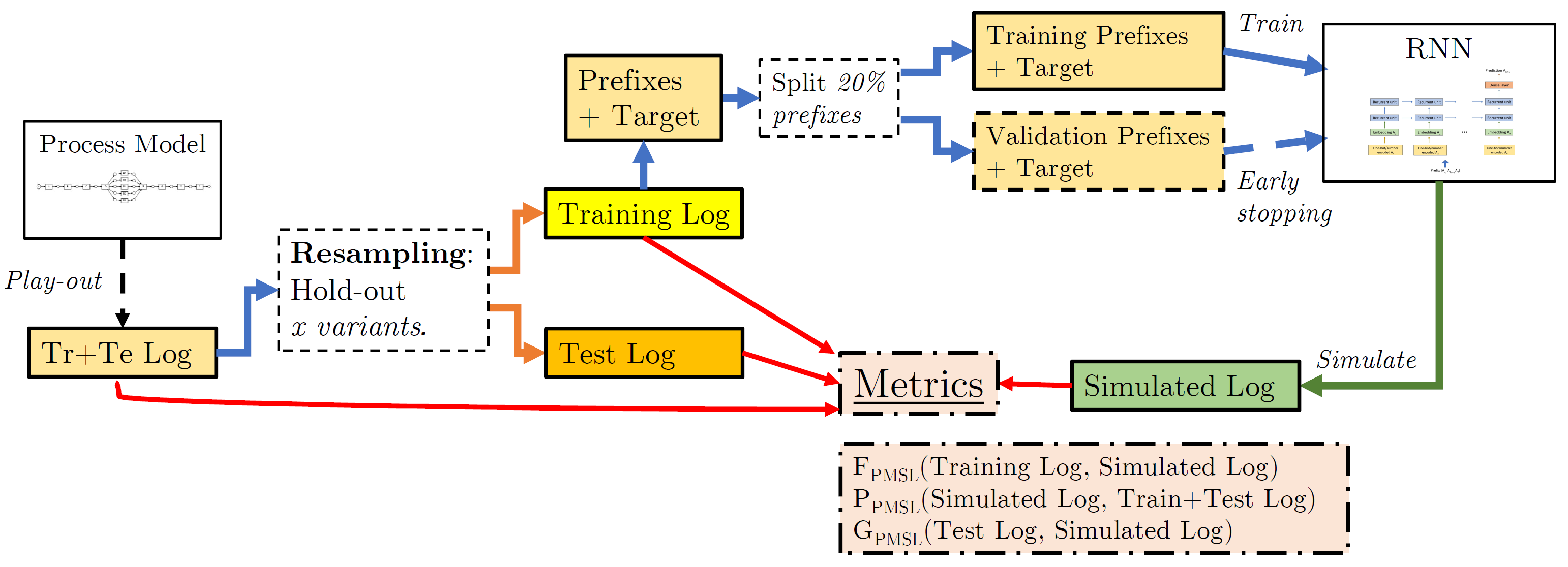
Validation set sampling
Previous studies investigating the efficacy of long short-term memory (LSTM) recurrent neural networks in predictive process monitoring and their ability to capture the underlying process structure have raised concerns about their limited ability to generalize to unseen behavior. Event logs often fail to capture the full spectrum of behavior permitted by the underlying processes. To overcome these challenges, this study introduces innovative validation set sampling strategies based on control-flow variant-based resampling. These strategies have undergone extensive evaluation to assess their impact on hyperparameter selection and early stopping, resulting in notable enhancements to the generalization capabilities of trained LSTM models. In addition, this study expands the experimental framework to enable accurate interpretation of underlying process models and provide valuable insights. By conducting experiments with event logs representing process models of varying complexities, this research elucidates the effectiveness of the proposed validation strategies. Furthermore, the extended framework facilitates investigations into the influence of event log completeness on the learning quality of predictive process models. The novel validation set sampling strategies proposed in this study facilitate the development of more effective and reliable predictive process models, ultimately bolstering generalization capabilities and improving the understanding of underlying process dynamics.
Publications
- Jari Peeperkorn, Seppe vanden Broucke, Jochen De Weerdt, “Validation Set Sampling for Predictive Process Monitoring”, Information Systems (2024), https://doi.org/10.1016/j.is.2023.102330
- Jari Peeperkorn, Seppe vanden Broucke, Jochen De Weerdt, “Can recurrent neural networks learn process model structure?”, Journal of Intelligent Information Systems (2022), https://doi.org/10.1007/s10844-022-00765-x
- Jari Peeperkorn, Seppe vanden Broucke, Jochen De Weerdt, “Can deep neural networks learn process model structure? An assessment framework and analysis”, Process Mining Workshops (ML4PM), ICPM 2021, https://doi.org/10.1007/978-3-030-98581-3_10